分布式事务详解 原理、挑战与实践方案
在当今互联网数据服务架构中,分布式系统已成为支撑大规模应用的核心基础设施。随着业务复杂度的提升和微服务架构的普及,分布式事务处理成为确保数据一致性和系统可靠性的关键技术挑战。本文将深入解析分布式事务的概念、核心原理、常见问题及主流解决方案。
一、分布式事务概述
分布式事务是指跨越多个网络节点(通常是不同的服务或数据库)的事务操作,这些操作要么全部成功提交,要么全部失败回滚,需要满足ACID特性(原子性、一致性、隔离性、持久性)在分布式环境下的延伸。
在典型的互联网数据服务场景中,用户的一次操作可能涉及订单服务、库存服务、支付服务等多个独立的业务单元,这些服务通常部署在不同的服务器上,拥有各自的数据存储,这就构成了一个典型的分布式事务场景。
二、分布式事务的核心挑战
- 网络分区与延迟:分布式系统中节点间的通信依赖网络,网络延迟、丢包、分区等问题会影响事务的协调和执行
- 节点故障:任何参与事务的节点都可能发生故障,导致事务状态不一致
- 数据一致性:在分布式环境下确保所有节点数据的一致性比单机系统复杂得多
- 性能与可用性平衡:强一致性往往以牺牲系统性能和可用性为代价
三、主流分布式事务解决方案
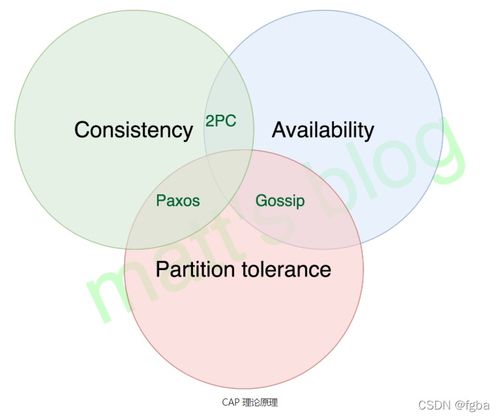
1. 两阶段提交(2PC)
两阶段提交是经典的分布式事务协议,包含准备阶段和提交阶段:
- 准备阶段:协调者询问所有参与者是否可以提交事务
- 提交阶段:如果所有参与者都同意,协调者通知所有参与者提交事务
优点:强一致性保证
缺点:同步阻塞、单点故障、数据锁定时间长
2. 三阶段提交(3PC)
在2PC基础上引入了超时机制和预提交阶段,解决了2PC的同步阻塞问题,提高了系统的可用性。
3. TCC模式(Try-Confirm-Cancel)
TCC通过业务逻辑层面的事务补偿机制实现最终一致性:
- Try阶段:预留业务资源
- Confirm阶段:确认执行业务操作
- Cancel阶段:取消预留的业务资源
适用于对一致性要求较高且业务逻辑复杂的场景。
4. 基于消息的最终一致性
通过消息队列实现异步的事务处理,配合本地消息表或事务消息确保数据的最终一致性,是目前互联网架构中广泛采用的方案。
5. Saga模式
将长事务拆分为一系列本地事务,每个本地事务都有对应的补偿操作,适用于业务流程长、涉及多个服务的场景。
四、实践建议与选型考量
在选择分布式事务方案时,需要综合考虑以下因素:
- 业务场景:根据业务对一致性的要求选择强一致性或最终一致性方案
- 性能要求:评估系统对吞吐量和响应时间的敏感度
- 系统复杂度:权衡方案实现难度和维护成本
- 技术栈兼容性:确保所选方案与现有技术栈良好集成
五、总结
分布式事务是构建可靠互联网数据服务的基石,理解不同方案的原理和适用场景至关重要。在实际应用中,通常需要根据具体业务需求和技术约束选择合适的方案,甚至组合使用多种方案来解决复杂的分布式事务问题。随着技术的不断发展,新的事务处理模式和实践也在不断涌现,持续学习和实践是掌握这一领域的关键。
如若转载,请注明出处:http://www.nirsiu.com/product/37.html
更新时间:2026-06-03 05:33:07